Introduction
Choosing a Virtual networking to connect VMs or Containers across Hosts is always a complicated decision. Most of us would have found the virtual networking on a single VM/Container Host to be very simple, easy to implement and debug. Just plug the VM/Container to a bridge and your are done. For access from the host, assign an IP to the bridge(you may need a NAT rule to access the internet from the VM, if you are doing private networks). But as we try to connect VMs/Containers across Hosts we are faced with a difficult choice, we can either go with a simple solution like VLANs and deal with physical switches or choose between the various overlay tunnel options.
Note for the impatient: If you are already aware of the paradigm of various virtual networking mechanisms, try the summary section which presents the solution in short.
VLANs are easy to debug but it needs configuration of the physical switches which are most often off limits. In a small office you might have a shared switch and any change in the switch configuration might impact the whole office. With multiple switches connecting your Hosts managing VLANs is complex (yes we can look at automation and management solution but that brings its own challenges). And sometimes we are also faced with unmanaged switches where VLANs are not an option.
Overlays on the other hand skip the need to have physical switch access and instead handle configuration at the (virtual switch on the) VM/Container host. The problem with this approach is the lack of visibility of the traffic (encapsulated packets) on the virtual network which makes debugging as much difficult. Another issue is the distributed nature of tunnel based Overlays, we have a full mesh of tunnels connecting each VM/Container host to all other hosts (debugging partial mesh and tunnels over UDP are more convoluted).
An alternative to this is to use a IP network to connect your Hosts, but for the this to work you need to subnet your IP range so that each of the Hosts can get its own subnet and allocate IPs to the VM/Containers from this subnet. The easiest approach is to take a huge (/16 or sometimes /8)subnet and curve out a subnet for each of the VM/Container Hosts. While planning such a network we need to keep in mind the future need to add more VM/Container Hosts and the maximum number of VM/Containers that a Host will ever support. Other IP based solution also depends on running routing protocols to synchronise routes across
Recently I faced the same dilemma while designing an automation framework for a hosting VMs across a group of Physical Host. VLAN of-course was the first choice due to its simplicity but we quickly saw the issue with accessing physical switch configuration and the problems of mis-configuration. (and even while using a management solution)
So I decided to investigate if I can design a virtual network with the following attributes
- No ARP storm
- No Routing Protocols (at least to start with)
- No Overlay
- No VLAN
- and no Complex Subnetting (see above)
The aim is to use the commonly available networking capabilities of linux kernel to provide network connectivity to the VMs on the virtual network.
In this blog I will present the design of my proposed solution.
The Simple Part
Let’s start with the simplest building block of the network. Connecting the VMs on a single Host. I decided to use a linux bridge to connect all VMs launched on a host on a given network. This means I will create one bridge per virtual network on the Host and all the VMs on this virtual network on the host will connect to this bridge. Assign IPs to your VMs within your network from the associated subnet and all the VMs can communicate to each other over the bridge. To provide connectivity from the Host to the VMs I also added an IP to the bridge from the same subnet range.
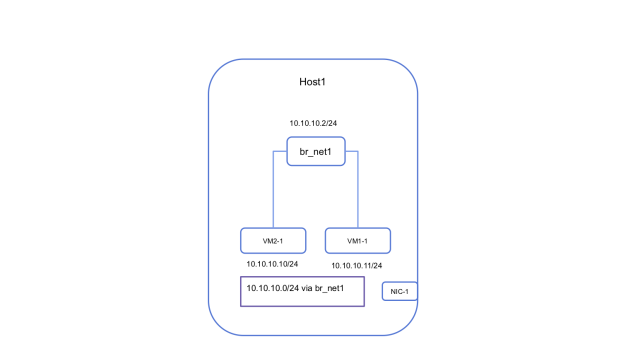
The following is the state of the routing table on the host after adding the bridge IP.
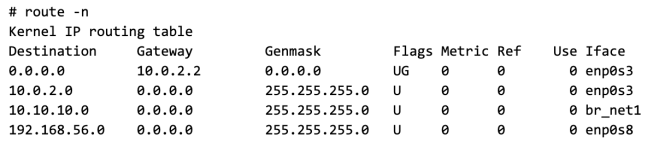
Note: I have 2 network interface on the Host (this is not necessary for the proposed network design, but just the way my Host is setup)
- enp0s3 connects to internet
- enp0s8 connects to the private lan, this is what I will use to connect the hosts
Connecting VMs on multiple Hosts
The above procedure can be replicated on other Hosts to start VMs and connect them locally. The only constraint here is that VM IPs should not conflict with each other.
For explanation, let’s say that we have started the following VMs on two different hosts on a network called net1 with associated subnet 10.10.10.0/24
| Host Name | Host IP | VM Name | VM IP |
| Host1 | 192.168.56.103 | VM1 | 10.10.10.10/24 |
| VM2 | 10.10.10.11/24 | ||
| Host2 | 192.168.56.104 | VM3 | 10.10.10.12/24 |
| VM4 | 10.10.10.13/24 | ||
| Router | 192.168.56.101 |
The bridge on each of the host are called br_net1 and is given an ip of 10.10.10.2/24(yes I am configuring the same IP on bridge on all the Hosts)
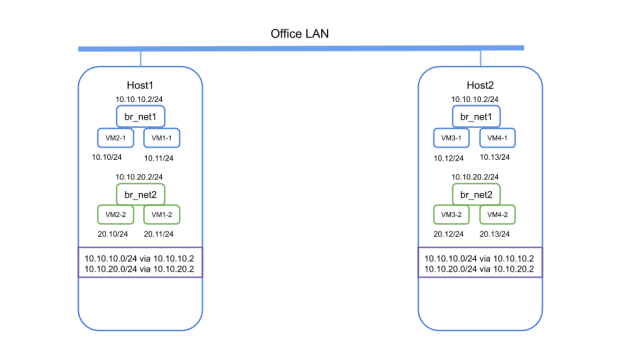
Now from the VM1 if we try to ping VM3 on Host2 it will fail as the bridge on Host1 has no knowledge of the MAC of VM3 as they are on two different L2 segments.
Resolving MAC address of remote VMs
To resolve the above situation I enabled proxy arp on the bridge. Please see my previous post for other examples where i used the same solution.
echo 1 > /proc/sys/net/ipv4/conf/br_net1/proxy_arp
This will allow the bridge to respond with its own MAC when an ARP query made by any connected VM and the destination IP is not known to the bridge.

In this example you can see that the MAC of VM3 (10.10.10.12) is same as that of the bridge(10.10.10.2)
Sending Packet to a remote VM
Once the Bridge responds to the ARP query, VM1 will send the ping packet to the bridge. The kernel on the Host1 now has to decide the where to route the packet for VM3 by doing a route lookup. Linux by default will not forward packets across directly connected networks. To enable this behavior we need to enable ip_forwarding on the Host.
echo 1 > /proc/sys/net/ipv4/ip_forward
Now if we can make sure that the correct route exists on Host1 to reach VM3, we will be able to complete half of the round trip for the ping packet.
Introducing the Router (just another Linux Machine)
To resolve the routing problem we introduce another component in to the picture, which is a router. The router is connected to the same LAN to which the Host1 and Host2 are connected and its IP is 192.168.56.101(mentioned in the table above).
Although we can eliminate the need for a router by programming the routes on the Hosts, that approach will need managing a distributed routing table configuration across hosts. Using a central router makes managing configuration simpler.

The router is programmed with the correct destination for each of the VM using host routes. Here is an example of the routing table on the Router.
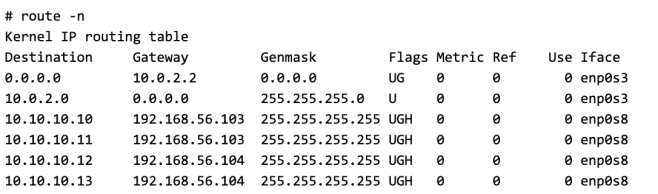
If we can send the packet destined to VM3 to this router, the router forward it to Host2(192.168.56.104) which we know in turn can forward it to VM3.
But first we have to solve another problem with routing.
Recalling from the previous illustration the routing table on the Host1 already has a route entry for net1 (10.10.10.0/24)
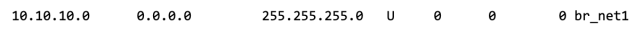
This is because the br_net1 interface is already configured with the ip of 10.10.10.2/24 and the linux kernel know that host1 is directly connected to net1. If we remove this route or the IP on the bridge the host cannot forward packets to the VMs connected to the bridge. With this route present we cannot forward packets on 10.10.10.0/24 to the router.
We will have the same configuration in the routing table of Host2 as Host2 is configured exactly the same way as Host1.
Resolving the Multiple route problem
To resolve this issue we will use policy based routing provided by linux kernel. You can get details of policy routing on linux in my previous post. In short policy based routing helps in route selection based on the attributes of the packet. In this case we will use the ingress port of the packet to decide which route to select for the packet.
Policy routing is enabled in two steps.
- Create an alternate routing table which will hold the custom routing rules
- Create a policy routing rule to select which table to use based on the properties of the packet
First we will create a separate routing table. The new routing table is identified by a routing table id (101) and name (sdn_net)
echo "101 sdn_net" >> /etc/iproute2/rt_tables
This table is configured with the following routes
ip route add 10.10.10.0/24 via 192.168.56.101 table sdn_net ip route add default via 192.168.56.101 table sdn_net
To view the route entries in the table use the following command

Now we will add routing rule to select the correct routing table when forwarding traffic. The routing rule is based on the follow condition
- if a packet enters the Host1 through the bridge br_net1 it must be trying to reach an IP not available on the VMs directly connected to the bridge. All such packets must be forwarded to the router and and so must use the new routing table we created.
- While if the packet enters the Host through of its other network interfaces it might be destined for the VMs and they can continue to use the main routing table as usual.
Use the following command to create the rule
# ip rule add iif br_net1 lookup sdn_net
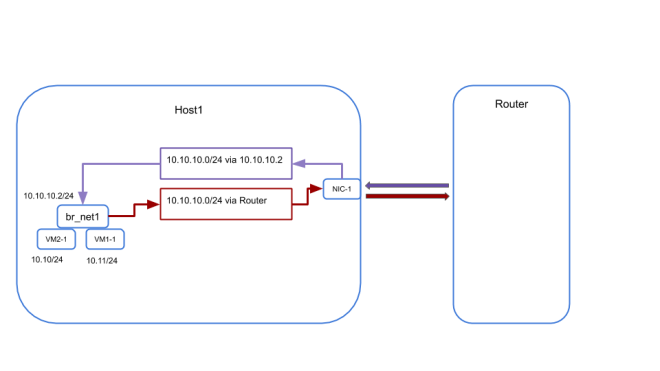
Once the new routing table and the policy routing rules are applied to both the hosts the ping packet can complete its complete path and you should have connectivity between VMs across Hosts
Running multiple virtual networks and routing between them
With the previous step we achieved connectivity between VMs on the same network, but how do we enable VMs on one network to communicate to VMs one another network?
To do this we need to have a gateway configured for each of the virtual networks.
- The VMs must be configured to use this gateway as the default route.
- Default route must be added to the alternate route table we created
- The gateway IP itself must be configured on the loopback interface on the router as a /32 address.
Once this is done for both the virtual network, VMs in one network can reach the VM on other.
Connecting to the internet
If you are creating network with subnets carved out of your office network (i.e. the IPs are routable in your office/home network you can make an route entry on your main router to forward all traffic for your virtual networks to the router we configured above and you should have internet connectivity.
But if you are running isolated virtual networks and the companies router does not have any configuration for your network. In that case you will need to apply NAT for all traffic going out of your virtual network.
A simple and manageable way to do this is to use iptables rule in conjunction with ipsets. To do this, create an ipset on the router as follows.
ipset create sdn_net hash:net
Add any network that needs Internet access to this ipset
ipset -A sdn_net 10.10.10.0/24
Following iptables rule can used to provide internet access.
iptables -t nat -A POSTROUTING -m set --match-set sdn_net src -j MASQUERADE
While using ipsets there is no need to change the iptables rule whenever a new virtual network is added or removed. Instead you can just update the ipset with the correct network list and iptables will pick it up.
Summary
Here is a quick summary how the virtual network works
- All VM on a network on a Host connect to a bridge
- All VMs and the bridge get an IP from the subnet associated with the network
- This creates a routing entry in the main routing table of the Host and makes the virtual network directly connected to the Host
- We enable proxy arping on the bridge to respond to any unanswered ARP query. This will be used to respond to the ARP queries for VMs hosted on remote hosts.
- We enable IP forwarding to make sure packet reaching the bridge due to proxy arping can be forwarded to other networks
- We add a router to the topology to forward traffic between VM on different Hosts and configure it with host routes for VMs
- Finally we solve the different routes for ingress and egress packets from the bridge using policy based routing rules and alternate routing table.
Trying it out
While it is possible to test this solution by setting up your own lab. I have written a python program to automat the test setup. To try it out you will need 3 test machine connected to the same LAN(Host1, Host2 and Router). These machines can be VM. I used network namespaces to simulate the VMs that are launched on Host1 and Host2. The script can run from any machine but needs SSH Key based access to the root account of the 3 Hosts. The code can be found here
Conclusion
So what are the advantage of using this network.
- Ease of deployment, no need to manage VLANs, configuring switches
- Ease of debugging, as all the features that we used are part of the linux kernel and mostly are layer 3 we can use regular debugging tools like ping, traceroute, tcpdump to debug the setup
- Easily extensible, as we are not constrained by subnetting, no of tunnels etc. we can scale the solution horizontally
- No ARP beyond the Host, any unanswered ARP queries originating in the VM are responded by the bridge. So your office switch never sees the ARPs from the VMs and the VM macs don’t overflow the mac tables of the physical switch
- As we are dealing with L3 packets we can use VRRP or ECMP for providing HA and Load Balancing