I was trying to figure out a way to match packets with a certain GRE key and take some action. IPTables does not provide a direct solution to this problem but has the u32 extension modules that can be used to extract 4 bytes of the IP header and match against a pattern.
So, I decided to give a try to this extension.
Prepare the setup
I created a tunnel between 2 of my VMs and assign IP address to the tunnel interfaces
On VM1
sudo ip tunnel add tun2 mode gre remote 192.168.122.103 local 192.168.122.134 ttl 255 key 22 sudo ifconfig tun2 6.5.5.1/24 up
On VM2
sudo ip tunnel add tun2 mode gre remote 192.168.122.134 local 192.168.122.103 ttl 255 key 22 sudo ifconfig tun2 6.5.5.2/24 up
Start with a basic rule
Next, created a IPTables rule on the receiving system to generate logs for packet match, but you can also create an ACCEPT rule and check the builtin packet counter for the rule.
sudo iptables -I INPUT -p 47 -m limit --limit 20/min -j LOG --log-prefix "IPT GRE" --log-level 4
Now start ping from VM2 to VM2
ping 6.5.5.1
You can keep a watch on the packet counters with the following command
watch "sudo iptables -L -v -n"
The GRE header
Next, a look at the GRE header format (taken from RFC https://tools.ietf.org/html/rfc2890). The header format is described in the RFC and it contains an optional 32bit key, which is the data of our interest.
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |C| |K|S| Reserved0 | Ver | Protocol Type | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Checksum (optional) | Reserved1 (Optional) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Key (optional) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number (Optional) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Run the following tcpdump command to capture the packets(My VMs don’t have GUI)
sudo tcpdump -s 0 -n -i ens3 proto GRE -w dump.pcap
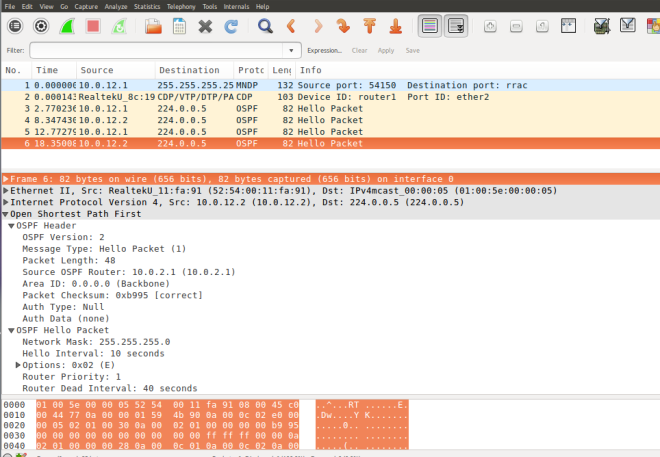
The captured packets can be analyzed using wireshark

Understanding the iptables u32 extension match rule
Basically u32 module is able to extract 4 byte of data from the IP header at a given offset and match with the given hex number or range. Here is an example of a u32 match rule from the man-page. It matches packets within a certain length. The man page describes the format of the rule, you provide an offset , u32 extracts 4 byte from the offset position, and then we AND it with the MASK and finally compare with the HEX value
Example: match IP packets with total length >= 256 The IP header contains a total length field in bytes 2-3. --u32 "0 & 0xFFFF = 0x100:0xFFFF" read bytes 0-3 AND that with 0xFFFF (giving bytes 2-3), and test whether that is in the range [0x100:0xFFFF]
The man page has more details.
Craft a match for GRE Key
The IP header length is 20 bytes and the GRE key starts at 24 bytes, as can be confirmed from the wireshark. At the beginning of the rule match starts at the IP header(highlighted in the wireshark screenshot)

Based on the example from the man page I crafted the following rule to match the GRE key.
sudo iptables -I INPUT -p 47 -m u32 --u32 "24 & 0xFFFFFFFF = 0x16" -m limit --limit 20/min -j LOG --log-prefix "IPT GRE key 22" --log-level 4
Checking for Key Present Flag
But the key can be optional. So, add match for Key-Present Flag.
sudo iptables -I INPUT -p 47 -m u32 --u32 "20 & 0x20000000 = 0x20000000 && 24 & 0xFFFFFFFF = 0x16" -m limit --limit 20/min -j LOG --log-prefix "IPT GRE key 22" --log-level 4
Here is a screen capture of the iptables packet counters
Chain INPUT (policy ACCEPT 294K packets, 78M bytes) pkts bytes target prot opt in out source destination 711 79632 LOG 47 -- * * 0.0.0.0/0 0.0.0.0/0 u32 "0x14&0x20000000=0x20000000&&0x18&0xffffffff=0x16" limit: avg 20/min burst 5 LOG flags 0 level 4 prefix "IPT GRE key 22"
The above rule is simplistic and good to get you started but has short comings, e.g. it assumes a constant IP header length.
The man page describes examples of how to handle variable length headers, fragmentation check etc.